# k_means_np.py
# K-means Clustering(군집화)
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
def distance(A, B): # column-wise, broadcasting
return np.sqrt( np.sum((A - B)**2, axis=1) )
num_puntos = 20000; n2 = np.int(num_puntos/2)
vectors = np.empty([num_puntos,2])
vectors[:n2,0] = np.random.normal(0.0, 0.9, n2)
vectors[:n2,1] = np.random.normal(0.0, 0.9, n2)
vectors[n2:,0] = np.random.normal(3.0, 0.5, n2)
vectors[n2:,1] = np.random.normal(1.0, 0.5, n2)
''' k 가지 분류 문제 '''
k = np.int( input('How many kind of classification ? '))
''' Create a k initial centroids of shape (k, 2) '''
np.random.shuffle(vectors)
centroids = vectors[np.random.choice(range(num_puntos), k)] # (4,2)
''' Iteration to make classification '''
c_old = centroids.copy()
for step in range(500):
# 각 좌표와 4-평균좌표와의 거리를 계산하여 가장 가까운 것으로 분류
assignments = [ distance(vectors, centroids[r]) for r in range(k) ]
assignments = np.argmin( assignments, axis=0 ) # (n, )
''' Update the centroides by 4-means '''
centroids = np.array([ np.mean( vectors[assignments==c, :], axis=0 ) for c in range(k) ])
if np.sum(distance(centroids, c_old)) < 1.0e-3: break
c_old = centroids.copy()
''' Result '''
print('The nbr of clustering points = ', num_puntos )
print('The number of k-means iteration = ', step )
''' Constructing a dictionary to plot '''
data = {"x": vectors[:,0], "y": vectors[:,1], "cluster": assignments }
''' Plot using seaborn '''
df = pd.DataFrame(data)
m = centroids
sns.lmplot("x", "y", data=df, fit_reg=False, size=6, hue="cluster", legend=False)
plt.plot(centroids[:,0], centroids[:,1], 'kd')
|
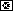  |
|